DB course
Transformed from Logseq page
DB course
-
public:: true
-
Algebra collapsed:: true
-
preliminaries: relation, attribute, schema, tuple, component, domain, current instance, key
-
operations collapsed:: true
-
- set ops: union, intersect, minus
- filter ops: select
- relation ops: product, joins
- mapping ops: rename, project
-
equivalence collapsed:: true
-
-
-
extended operators collapsed:: true
-
deduplicate
-
aggregation
-
grouping
-
outer join (left,right, and theta)
-
sorting
-
-
datalog
-
-
Formalization collapsed:: true
-
FD collapsed:: true
-
key -> tuple and key is minimal, superkey is superset of key
-
rules collapsed:: true
-
transitive
-
splitting
-
combining
-
trivial
-
argumentation: {As}->{Bs} => {As,Cs}->{Bs,Cs} collapsed:: true
-
=>{As,Cs}->{Bs} (splitting) one case where rule 3 in (((6365fd79-49de-48d7-acdb-c5507b7d425d)) counts
-
-
-
closure collapsed:: true
-
-
{superkey}+={all attributes}
-
check whether a FD follows from a given set
-
-
minimal basis id:: 6365fd79-49de-48d7-acdb-c5507b7d425d
- 1.All the FD’s in B have singleton right sides.
- 2.If any FD is removed from B, B is no longer a basis.
- 3.If for any FD in B we remove one or more attributes from the left side of F, the result is no longer a basis (why?)
-
projecting
-
minimize collapsed:: true
-
remove those follow from others
-
remove left side redundancy
-
-
-
BCNF collapsed:: true
-
any FD As->Bs, As is superkey
-
decompose: not dependency preserving
-
chase test for lossless join
-
-
3NF collapsed:: true
-
dependency preserving
-
any FD As->Bs, As is superkey or Bs are each in a key
-
decompose: find min-basis, a relation for each FD, add a key relation
-
-
MD collapsed:: true
-
intuitively, As->->Bs holds if As determine a set of values of Bs.
-
trivial: As ->-> subset of As, As->->\As(others=)
-
FD promotion: As->Bs => As->->Bs(in tabular test, )
-
transitive
-
complementation: As->->Bs => As->->others
-
4NF collapsed:: true
-
any MVD As->->Bs, As is superkey
-
-
chase test: initially two tuples t and u, use FDs and MVDs to produce v
-
projecting collapsed:: true
-
simplification(not reviewed)
-
-
-
E-R Model collapsed:: true
-
many->one(less than), many->one(exactly, rounded arrowhead), many—(degree constrains)many, roles
-
multiway relations -> relation entity&multi binary relations
-
isa(subclass relationship) collapsed:: true
-
differs from object-oriented approach, entity may be in multi sub entity sets
-
root entity set
-
-
remove redundant entity set: referred once in relation, all attrs are in key
-
weak entity set (and its supporting relationship) collapsed:: true
-
def: key is composed of attributes , some or all of which belong to another entity set
-
-
convert to relational design collapsed:: true
-
combining many-one relationship to many side
-
weak entity set: don’t need supporting relation
-
classes: null method, OO method(enumerate all subtrees)
-
-
-
Hard Problems collapsed:: true
-
collapsed:: true
设有关系 R(A,B,C,D,E,P),F={AB→C,C→D,E→A,B→C,CA→E,BD→A} 1、写出关系 R 的所有候选键,并指出关系 R 为第几范式。要求说明原因。 (4 分) 2、求出该函数依赖集的最小集 Fm。写出求解过程。 (7 分) 3、将 R 分解为具有无损连接性和依赖保持性的 3NF。写出分解过程。 (5 分)
-
Fm={B->C,C->D,E->A,AC->E,B->A}
-
-
-
-
SQL lang collapsed:: true
-
components
- DDL: data definition lang, schema and constraint etc.
- DML: data manipulation lang, query and transaction etc.
- DCL: data control lang, permission and grant etc.
-
relations: stored, view, temp tables
-
schema collapsed:: true
-
CREATE TABLE/VIEW <name> (...)collapsed:: true-
inline constrains after attribute
-
or table-wise constrain after all attrs
-
-
DROP TABLE/VIEW <name> (...) -
ALTER TABLE/VIEW <name> (...)
-
-
query collapsed:: true
-
sqlSELECT <> FROM <table>[alias],... WHERE{ CONDITIONS } GROUP BY () HAVING <condition> -
operators collapsed:: true
-
not equal
<> -
pattern matching:
_,%,'','pattern' ESCAPE '<escape char>' -
NULL: calc result is NULL, comparison result is UNKNOWN
-
EXISTS,[NOT] IN,> ALL,> ANY(existence) -
CROSS JOIN,a JOIN b ON <c>,FULL|LEFT|RIGHT OUTERJOIN -
set operators normally eliminates duplicate, use
a UNION ALL bto avoid
-
-
-
modification collapsed:: true
-
-
SQL other features collapsed:: true
-
Constraint collapsed:: true
-
kinds collapsed:: true
-
default value
-
key
- primary key not nullable, unique nullable
- can’t agree on all attrs, unless one is null
- two nulls don’t agree on each other
-
foreign key collapsed:: true
-
policy: CASCADE, SET NULL, DEFAULT(reject)
-
-
not null
-
trivial
check -
assertion collapsed:: true
-
CREATE ASSERTION xxx CHECK (...)
-
-
-
naming
-
defer collapsed:: true
-
[NOT] DEFERRABLE [INITIALLY DEFERRED/IMMEDIATE] -
SET CONSTRAINT xxx DEFERRED
-
-
scope collapsed:: true
-
attribute: checked only when target attribute changes
-
tuple: checked more frequently
-
table(assertions)
-
-
-
Trigger collapsed:: true
-
plaintextCREATE TRIGGER XXX AFTER|BEFORE|INSTEAD-OF UPDATE|DELETE|INSERT ON <table> REFERENCING xxx FOR EACH ROW|STATEMENT [WHEN <condition>] [BEGIN] statements; [END]
-
-
View collapsed:: true
-
updatable view
-
using instead of trigger
-
materialize view
-
-
Index collapsed:: true
-
estimate query cost (simple) collapsed:: true
-
tuple locate collapsed:: true
-
by index, 1r per index access
-
no index, full table scan
-
-
tuple access collapsed:: true
-
if clustered, then may be 1r
-
else num of pages tuple is distributed
-
-
tuple insert collapsed:: true
-
usually zero-cost to find a slot
-
1r per index update
-
-
-
-
-
Storage collapsed:: true
-
disc access model collapsed:: true
-
find track -> move to track -> wait for spinning -> start transferring collapsed:: true
-
move to track: head start/stop + head move(n-tracks/velocity)
-
TODO spinning: half?avg? :LOGBOOK: CLOCK: [2022-11-02 Wed 08:31:22]—[2023-04-16 Sun 16:27:16] => 3967:55:54 :END:
-
transferring: size-block(sectors+gaps)/size-track * time per rotation
-
-
-
physical optimize collapsed:: true
-
organize data by cylinders
-
mirroring disks collapsed:: true
-
enhance reliability
-
speed up reading(different part per disk) not writing
-
-
scheduling collapsed:: true
-
elevator algorithm
-
-
intelligent buffering
-
-
robustness collapsed:: true
-
checksum
-
redundant storage(stable storage, RAID) collapsed:: true
-
TODO RAID 4(one main disk, bottleneck) 5(symmetric backup) 6(multiple ) :LOGBOOK: CLOCK: [2022-11-02 Wed 09:25:01]—[2023-04-16 Sun 16:27:21] => 3967:02:20 :END:
-
-
-
storage format collapsed:: true
-
schema collapsed:: true
-
number of fields, type, order, name
-
-
fixed-length format collapsed:: true
-
header collapsed:: true
-
pointer to schema, length, timestamp
-
-
-
variable-length format collapsed:: true
-
a pointer to other than first variable field
-
header->pointers->fixed-fields->var-fields
-
dedup in-record by another level pointers
-
separate variable fields
-
spanned records
-
-
pack into blocks
-
header collapsed:: true
-
one or more other blocks
-
role of this block(normal data or overflow)
-
which relation the records belongs to
-
record offsets collapsed:: true
-
real offset in-block
-
or forwarding address to another block
-
or tombstone indicating it’s deleted
-
-
timestamp
-
-
two-ends growing to center collapsed:: true
-
variable header and record length
-
-
-
-
addressing collapsed:: true
-
physical disk address
-
logical address collapsed:: true
-
more compact
-
tradeoff: flexibility <-> cost collapsed:: true
-
e.g. move records of indirection
-
-
logical->phisical
-
logical->memory
-
-
pointer swizzling collapsed:: true
-
avoid repeatedly translating addr
-
strategies collapsed:: true
-
automatic
-
on demand
-
-
unswizzling when returning to disk collapsed:: true
-
need mem->logical indexing
-
-
-
pinned records and blocks collapsed:: true
-
pinned: object is referred to by a swizzled pointer
-
use spare bytes(logical-memaddr) to make a linked list
-
-
-
modification collapsed:: true
-
insertion
-
deletion collapsed:: true
-
immediate reclaim space
-
mark delete
-
-
update collapsed:: true
-
fixed-length easy
-
dynamic via deletion&insertion
-
-
-
-
Index collapsed:: true
-
types collapsed:: true
-
dense: one by one key-pointer pairs
-
sparse: adjacent entries determine a range corresponding to keys
-
multi-leveled
-
secondary collapsed:: true
-
must be dense
-
-
indirection collapsed:: true
-
reduce replicated key entries
-
key->bucket of many pointers->tuple
-
-
revert index(document retrieval)
-
-
data structures collapsed:: true
-
B-trees collapsed:: true
-
rules
- node min item
- leave node
- multiset case: min new key, blank key
-
insertion and deletion
- recursively split
- borrow from sibling node
-
-
hash table collapsed:: true
-
extensible hash table collapsed:: true
-
bucket directory
- initially first 1 bit
- once bucket used up, split the bucket, use k+1 bits, other buckets still remain unchanged
- once directory length not enough, double the directory, b0/b1 points to same bucket
-
-
linear hash
-
-
-
multi dimensional collapsed:: true
-
partial match, range, nearest-neighbor
-
hash like approach collapsed:: true
-
grid file collapsed:: true
-
dynamic insertion: overflow block, or insert grid line
-
hard to find optimal split
-
-
partitioned hashing collapsed:: true
-
good at partial match
-
-
-
tree like approach collapsed:: true
-
kd-tree
- long search path
-
R-tree
-
-
bitmap approach collapsed:: true
-
field -> collection of bitmaps, one bitmap per value
-
compressed bitmap
- run-length encoding
-
-
-
exercise collapsed:: true
-
3.1 线性表删除时如何处理位数i减少
-
3.2 hard h(k)的每一位都相同无法区分,若重复数多于bucksize如何split
-
7.5 如何编码趋近
-
-
-
Exec
-
Physical Ops
-
one pass
-
two pass
-
sort
-
index
-
hash
-
-
algebra simplification
-
cost model
-
logical & physical plan
-
exercise
-
4.3.2
-
4.3.5
-
4.4.5、4.4.8 子表少于M如何利用空闲缓冲区
-
4.5.5 考虑磁盘IO特性,计算开销
-
-
-
Schedule collapsed:: true
-
serializability
-
conflicts: ignore actions from same trans conflict equiv: by transforming non-conflict ops conflict serializable: conflict equiv to some serial schedule view serializable: ignore blind write
-
lock
-
shared-exclusive
-
upgrading lock collapsed:: true
-
shared->upgrade: may lead to deadlock collapsed:: true
-
update lock: may later write, singleton but can coexist with shared
-
-
-
increment lock
-
procedure
-
naive lock -> 2PL: conflict serializable, unlock after all locks
-
lock table collapsed:: true
-
group mode
-
lock list: waiting and holding
-
grant policy
-
-
-
granularity collapsed:: true
-
intention lock collapsed:: true
-
组模式,某种锁优于另一种
-
-
tree protocol collapsed:: true
-
观察到无需对父节点修改时unlock
-
-
-
-
deadlock
-
timestamp&validation collapsed:: true
-
read/write too late
-
uncommited TX may abort -> delay until determined
-
-
exercise collapsed:: true
-
 collapsed:: true
collapsed:: true-
r1a,w1a,r1b,w1b,r2b,w2b,r2a,w2a r2b,w2b,r2a,w2a,r1a,w1a,r1b,w1b 注意到其对A、B的操作有交换律,
-
Compare with 18.2.3
-
-
2.4
-
2.6 r3c,r1a,w1c,r2a,w2b,r3b
-
3.1? collapsed:: true

-
case serial: 2 case interleave: 1A,2B->1B; 2B,1A->1A; 因此只有1A2B/1B2A两组内部可交替,共
-
-
4.1 会发生什么怎么说?
-
4.6
-
4.7 所有的?更新?如何考虑锁? a. r2c; b. i2c,i1b; c. u1b; d. w1b;
-
-
-
Transaction collapsed:: true
-
failure recovery collapsed:: true
-
undo
- write log->write disk->commit, commit data
-
redo
- write log->commit->write disk, commit log
- checkpoint: commit data
-
undo/redo *
-
checkpoint
- 避免向前追溯
start ckpt(Ti); end ckpt,若有end则Ti无需恢复start ckpt(Ti)中的Ti似乎可以省略?
-
logical log collapsed:: true
-
logical equiv, compensating action
-
-
-
recoverability collapsed:: true
-
(读)依赖的值必须先commit
-
日志落盘顺序需与产生顺序一致(group commit)
-
cascading rollback: dirty data, ACR调度, strict locking
-
rollback policy collapsed:: true
-
block: cache refresh
-
smaller: using log
-
-
-
exercise collapsed:: true
-
1.1 2PL和严格封锁的区别? strict只有在事务结束时才能统一释放所有w锁
-
1.4 “恢复时产生脏读”?
-
1.5 又是数调度!
-
2.6
-
6.2.2 如何计数 归纳递推,转换为向中插入O1
-
-
-
Course Project collapsed:: true
-
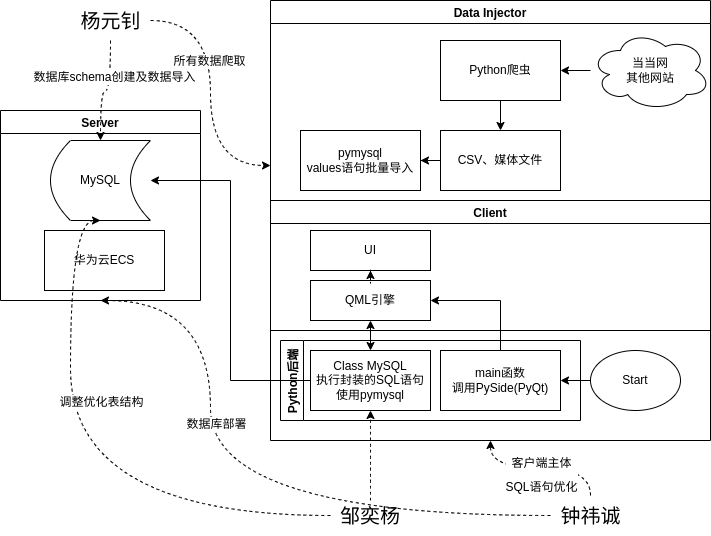
杨元钊、钟祎诚、邹奕杨
-
架构: 整体为C/S架构,Server端采用MySQL数据库,Client使用Python+QtQuick开发。其中Server部分使用一台华为云ECS,根据MySQL官网指示部署了MySQL 8.0(最初使用docker部署,但性能低于常规值3个数量级,后期推测是由于ECS的虚拟化云硬盘IO延迟高)。Client部分为Qt前端+Python后端,主程序由Python调用PySide(Qt)运行QML引擎,引擎运行QML代码实现界面显示与交互,QML代码通过引擎调用后端类获取数据;后端类使用pymysql执行编写好的SQL语句与数据库交互。
-
分工: 杨元钊负责数据的爬取清洗及数据库Schema的设计、创建; 邹奕杨负责客户端后端类的编写、SQL语句的编写及部分语句优化; 钟祎诚负责服务端的部署、客户端整体和UI部分的编写、SQL优化。
-
-
Linked References (5)
pg exec #DB course
-
ExecFinish 处理向client返回结果之外的副作用
-
计入执行时间
-
触发器、未完毕的写操作(如只需返回3条,但需更改所有)
-
-
事务虚实ID
- 进程、进程内计数
- 全局唯一性,进程内、进程、不同次运行中进程号可能相同
-
CLog与XLog,事务管理信息与数据信息分别存储
simple strategy to identify queries worthy of optimization: don’t optimize queries below a threshold #DB course
DONE review 1-7 chapters #DB course DEADLINE: <2022-11-01 Tue> :LOGBOOK: CLOCK: [2022-10-27 Thu 23:07:00]—[2023-04-16 Sun 16:26:52] => 4097:19:52 :END:
DONE two weeks’ homework #homework #DB course DEADLINE: <2022-11-02 Wed> :LOGBOOK: CLOCK: [2022-10-27 Thu 23:05:37]—[2022-11-02 Wed 23:26:08] => 144:20:31 :END: